Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao Princeton University
We introduce the Sheared-LLaMA models, the strongest 1.3B and 2.7B public base large language models (LLMs). Our models are produced by LLM-Shearing, an efficient method of constructing LLMs by first pruning a larger existing model and then continually pre-training it. Sheared-LLaMA models are first pruned from the LLaMA2-7B model, and then trained on only 50B tokens, 5% budget of the previous strongest public 3B model.
Paper: https://arxiv.org/abs/2310.06694 Code: https://github.com/princeton-nlp/LLM-Shearing Models: Sheared-LLaMA-1.3B, Sheared-LLaMA-2.7B

Table of Contents
Highlight of our results
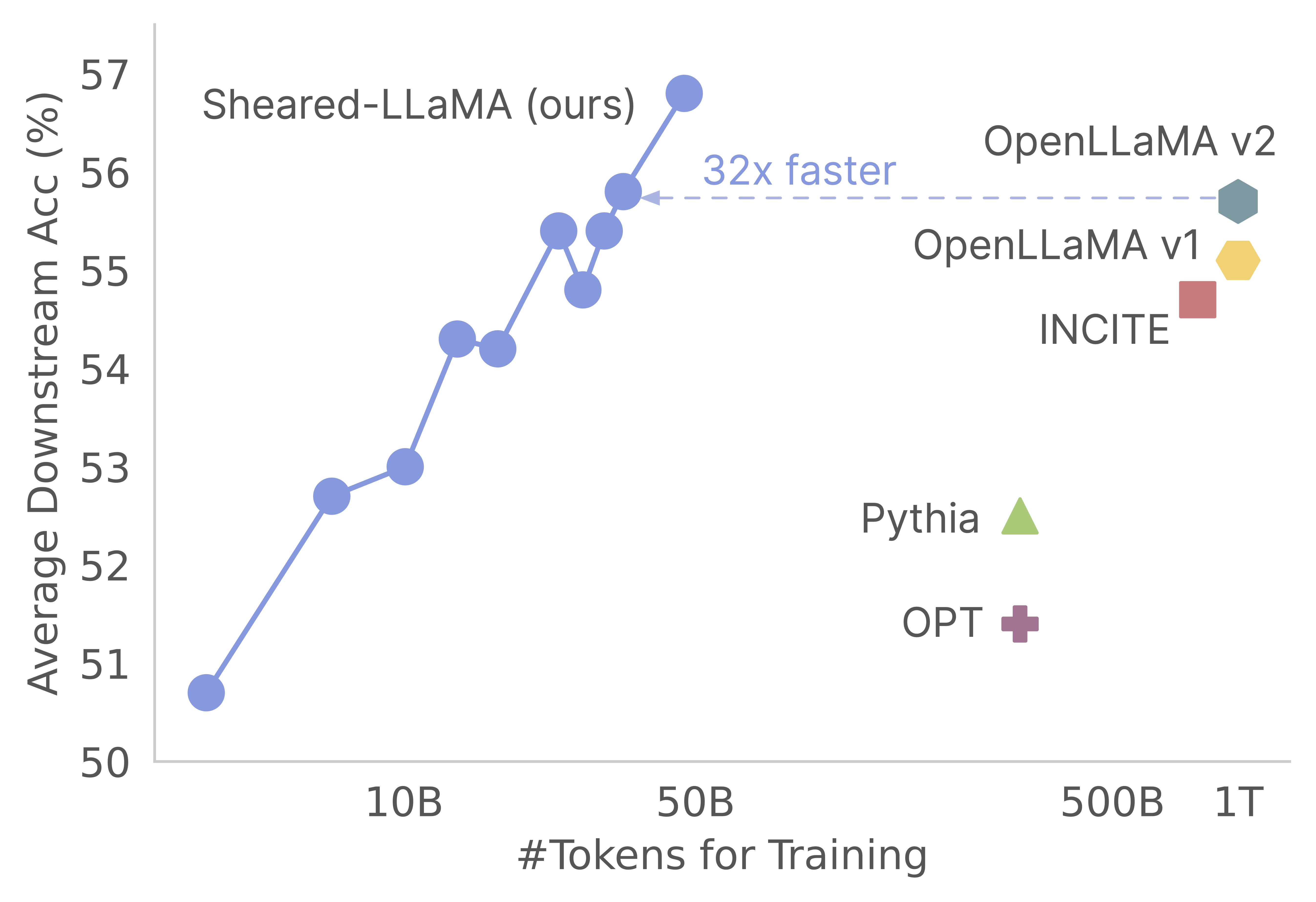
- Sheared-LLaMA-2.7B achieves better performance than existing open-source models of the same scale with 3% (1/32) of the compute.
- The trajectory shows a compelling case that if we invest more tokens and compute, the capability of Sheared-LLaMA can be further improved.
Swift Iterations of Open-Source LLMs
| Model | Date | Model Scale | Training Tokens | Training Corpora |
| Pythia | 02/13/2023 | 70M - 12B | 300B | The Pile |
| LLaMA | 02/27/2023 | 7B - 70B | 1T | RedPajama* |
| INCITE | 05/05/2023 | 3B - 7B | 800B | RedPajama |
| OpenLLaMA-v1 | 06/07/2023 | 3B - 13B | 1T | RedPajama |
| OpenLLaMA-v2 | 07/07/2023 | 3B - 13B | 1T | RedPajama, StarCoder, RefinedWeb |
| LLaMA2 | 07/18/2023 | 7B - 70B | 2T | Unknown |
| Mistral | 09/28/2023 | 7B | Unknown | Unknown |
*RedPajama is a public reproduction of the LLaMA training data.
Various institutions are actively and consistently releasing more capable open-source LLMs, trained with an increasing amount of compute. Despite their comparatively smaller sizes in comparison to proprietary models (GPT-4, Claude, PaLM), training these open-source models remains a costly endeavor. To put it into perspective, the training process for a LLaMA2 7B model, for instance, demands a substantial 184,320 A100 GPU hours. In this blog post, we introduce our methodology to accelerate pre-training via pruning existing strong LLMs.
Overview
Research Question
Can we produce a smaller, general-purpose, and competitive LLM by leveraging existing pre-trained LLMs, while using much less compute than training one from scratch?
Our answer is yes! And surprisingly, the compute savings will be tremendous. Specifically, We use structured pruning to achieve this goal. To link the approach to some past works:
- The utilization of pre-existing larger language models for training is not new
- Reduce, Reuse, Recycle (Blakeney et al., 2022) shows than distilling from an existing LM is more compute-efficient
- Large Language Model Distillation Doesn’t Need a Teacher (Jha et al., 2023) shows that the prune and continue pre-training recipe leads is more cost effective than distillation
- Pruning has been widely studied as a model compression technique
- Task-specific structured pruning (Xia et al., 2022, Kuric et al, 2023) retains the performance of large models with a moderate sparsity
- Task-agnostic pruning inevitably leads to performance degradation compared to the large model (Frantar et al., 2023, Sun et al., 2023, Ma et al., 2023)
Our Approach: LLM-Shearing
We propose two techniques in LLM-Shearing:
Targeted structured pruning: We prune a source model to to a pre-specified target architecture (e.g., an existing model's config), and meanwhile maximizing the pruned model’s performance
Dynamic batch loading: Pruning results in varying information retainment across domains. Inspired by (Xie et al., 2023), we load more data for domains that recover slow, and the loading proportion is dynamically decided on the fly.
Combining these two steps allow us to produce a smaller model
- With a specified model shape
- Reaching a target performance more efficiently
Future Implications
- Increasing computational resources will undoubtedly enhance performance.
- The stronger the initial base model, the stronger the resulting pruned model will be; repeatedly pre-training to outperform is not a cost-effective approach.
- Our approach is applicable to models of varying architectures and scales.
Performance
Downstream Tasks
We evaluate on an extensive set of downstream tasks including reasoning, reading comprehension, language modeling and knowledge intensive tasks. Our Sheared-LLaMA models outperform existing large language models.
| Model | # Pre-training Tokens | Average Performance |
| LLaMA2-7B | 2T | 64.6 |
1.3B
| OPT-1.3B | 300B | 48.2 |
| Pythia-1.4B | 300B | 48.9 |
| Sheared-LLaMA-1.3B | 50B | 51.0 |
3B
| OPT-2.7B | 300B | 51.4 |
| Pythia-2.8B | 300B | 52.5 |
| INCITE-Base-3B | 800B | 54.7 |
| Open-LLaMA-3B-v1 | 1T | 55.1 |
| Open-LLaMA-3B-v2 | 1T | 55.7 |
| Sheared-LLaMA-2.7B | 50B | 56.7 |
Instruction Tuning
We instruction-tuned Sheared-LLaMA and other public LMs of similar scale on ShareGPT and evaluate their open-ended generation ability by GPT-4. We show that Sheared-LLaMA’s instruction following ability is also better.

Continual Pre-Training
When compared to continuing pre-training an existing LM and a pruned model with the same amount of compute, we find that continuing pre-training the pruned model leads to a consistently better performance. When there exists a larger source model that is significantly stronger than all existing smaller ones (e.g., LLaMA2-7B is superior compared to all 3B models), pruning from the larger model is more cost-efficient than continually training existing small models.
Consider using it!
We propose a pruning approach LLM-Shearing which
- Accelerates pre-training: more cost effective than training models from scratch when competitive large LLMs are readily available
- Is Extensible to new models: easily adaptable to newly emerged and strong LLMs such as Mistral-7B, and bigger and better-curated pre-training data, such as Dolma, RedPajama, SlimPajama
- Is Extensible to models of any scales: though we only conduct experiment at the 7B scale, this method is applicable to LMs of any scales.
If you pre-train stronger LLMs with better data compositions or new data:
- Consider starting from a strong existing model, and prune it down to your target scale
If you are a LLM practitioner who are looking for strong small-scale LLMs to prototype your experiments:
- Check out our Sheared-LLaMA series on HuggingFace!
- We will keep producing small-scale models when more LLMs are released!